As psychological scientists, we like to talk about statistical power. There are some classic articles urging us to take power very seriously. And running underpowered studies, we are told, is a Bad Thing. Don't believe me? Here's a paragraph from a recently published paper (:cough: shameless self-serving plug :cough:) talking about how power is pretty important:
Power matters. The negative consequences of conducting low power research are well documented (e.g., Cohen, 1962; 1992a; 1992b). For example, low power research inflates the share of Type I errors in the published literature (Overall, 1969), makes it difficult for researchers to detect genuine effects (e.g., Cohen, 1992a), and severely hampers replication efforts. Researchers’ opinions are nonetheless disproportionately swayed by low power, statistically significant results (Tversky & Kahneman, 1971).
That paragraph cites only five papers. The papers on average are nearly 40 years old. They've been cited on average more than 3700 times apiece (with the Overall paper being the weakest link at an unfortunately paltry 37 citations). See, we take power very seriously! Seriously enough to cite the hell out of papers telling us that we should take power very seriously.
Talk's pretty cheap, and citations are only a little more expensive. How about actions? Do we act like we take power seriously?
Well, maybe not as much. In 1962, Cohen estimated typical power in a prominent journal, and it wasn't very high (something like .46 for a medium sized effect). But hey, that was 1962, and we learned our lesson, right? Well, Sedlmeier and Gigerenzer looked at the same journal about a quarter of a century later, and power actually decreased to .37. But hey, that was 1989, and we learned our lesson, right?
Maybe not. A ton of recent articles have pointed out that our power doesn't really seem to be increasing. But hey, maybe this is just a problem for research appearing in low-prestige journals, right? Not so much.
We seem to love talking about how important power is. But we keep on running low power studies, getting them published in flagship journals, and then citing them a ton. What gives?
Incentives, perhaps?
The current incentive system in social psychology seems heavily driven by appraisals of research productivity. Raise your hand if you've heard a visiting speaker or job candidate introduced in roughly this way:

Dr. Kovacs
Dr. Walter Kovacs has published 18 kajillion papers in prestigious journals like Science, Nature, JPSP, Psych Science, and Rangifer.
Okay, put your hands down. Yes you, everyone.
Don't get me wrong, it's easy to judge the excellence of researchers with crude heuristics like publication counts and recognition of the journals they frequent (note to self: start studying reindeer so I can submit something to Rangifer). And what's a good way to publish lots of papers? Run lots of studies!!!
Researchers have finite resources (time, energy, participants) at their disposal. So there's an inevitable tradeoff between 1) the resources one spends on any single project, and 2) the number of projects one can attempt. And if we are explicitly or implicitly rewarding productivity with things like jobs, tenure, and awards, then the number of projects might outweigh the individual effort one puts into any given project.
This is easy to see when you consider finite participant pools. Let's say you have access to 2000 participants per year. For the sake of simplicity, let's say you only run 2 condition, between subjects designs. Should you run 40 studies with 25 participants per condition, or 10 studies with 100 participants per condition? Sheer productivity recommends the former strategy. But, given the same underlying effect size, this means that the former strategy is drastically sacrificing power to achieve productivity. This is something that I've been thinking about a lot over the past couple of years (see blog posts about it here and here). Good methods demand power, yet our incentive structure seems biased in favor of productivity. Hence we have a situation where 50 years of harping about power haven't gotten researchers to make choices to increase power.
So, we (myself and talented graduate students Jenna Jewell, Maxine Najle, and Ben Ng...hire them when you get the chance!) decided to run an experiment to see what the incentive structure might look like, and to see if we can push the incentives around somehow.
The experiment
Last summer, we thought it would be fun to come up with an idealized little thought experiment to see how we social psychologists evaluate and reward methodological decisions and their consequences for both productivity and power. Now, there are tons of academic bottlenecks that one must navigate (getting a paper published, getting a job, getting grants, getting tenure). And presumably the power/productivity tradeoff is in play at each of these bottlenecks. We picked the Get a Job bottleneck because it seemed like the most tractable bottleneck. And, since the research team consisted of a recent PhD, a soon-to-be PhD (now Dr. Jewell), and two young grad students (now Masters Najle and Ng), jobs are pretty salient. We decided to create two fictional job candidates who were pretty much identical, but differed in how many participants they use in any given study:
Imagine two hypothetical job candidates. They're similar in a lot of ways. Both of them run 2000 participants per year. Their hypotheses tend to be right half of the time. They use simple 2-group experimental designs (between subjects). And they study similar phenomena, with similar effect sizes (Cohen's d = .4, which is typical for social psychology as a whole). Neither candidate employs questionable research practices.
Then, we decided to do some straightforward calculations about how each candidate would fare over a 5 year span if they ran experiments with either 25 (Candidate A) or 100 (Candidate B) participants per condition. Given the power they're respectively working with and the number of participants they have, these calculations are pretty straightforward. Using the calculations highlighted in this blog post, here's how the two fared, in terms of statistically significant findings, proportion of significant findings coming from false positives, and expected replication rates (at 1N):

There you have it! With the information provided, we'd expect Candidate A to be 56% more productive, despite running at 28% power. But that productivity comes at a price: lots of the significant results are false positives (Type I error), and it's pretty tough to replicate the results.
So, which candidate will people prefer?
We asked a bunch of participants to choose between the candidates, but we experimentally manipulated the information each participant received. All of them received the general preamble quoted above ("Imagine two....research practices."). Participants in the Findings condition only found out how many findings they had. Participants in the Sample Size condition also found out how many participants per condition. Participants in the Consequences condition also found out about calculated false positive and replication rates.
Job Candidate A runs experiments with 25 participants per condition (50 participants per experiment).
Job Candidate B runs experiments with 100 participants per condition (200 participants per experiment).
Over the past 5 years, Job Candidate A has published 33 statistically significant experiments. Of these 33 significant findings, 15% of them are false positives. In exact replication attempts, Candidate A’s statistically significant experiments are successfully replicated 25% of the time.
Over the past 5 years, Job Candidate B has published 21 statistically significant experiments. Of these 21 significant findings, 6% of them are false positives. In exact replication attempts, Candidate B’s statistically significant experiments are successfully replicated 76% of the time.
Findings condition = only the bolded text
Sample Size = bold text + italic text
Consequences = everything
It's important to note that participants in the Sample Size condition had all of the information that it would take to calculate the consequences. We just made those consequences explicit in the Consequences condition. But in principle, every participant in the Sample Size condition could've reached the same conclusions.
So , we sent this survey out to the membership list of the Society of Experimental Social Psychology, the top society in my field. One hundred and seventy something researchers were generous enough to take a dumb little survey sent out in an annoying email from some peon Assistant Prof who lives in a state that nobody ever visits. Now would be a good time to again sincerely thank everyone who was willing to click the link and spend their valuable time helping us out!


Each participant would make a hiring choice between Candidate A and Candidate B. Then, just for fun, we also asked participants to guess at 1) the typical effect size they study, 2) their typical sample size, and 3) how often they think their hypotheses are right, independent of statistical significance.
The results
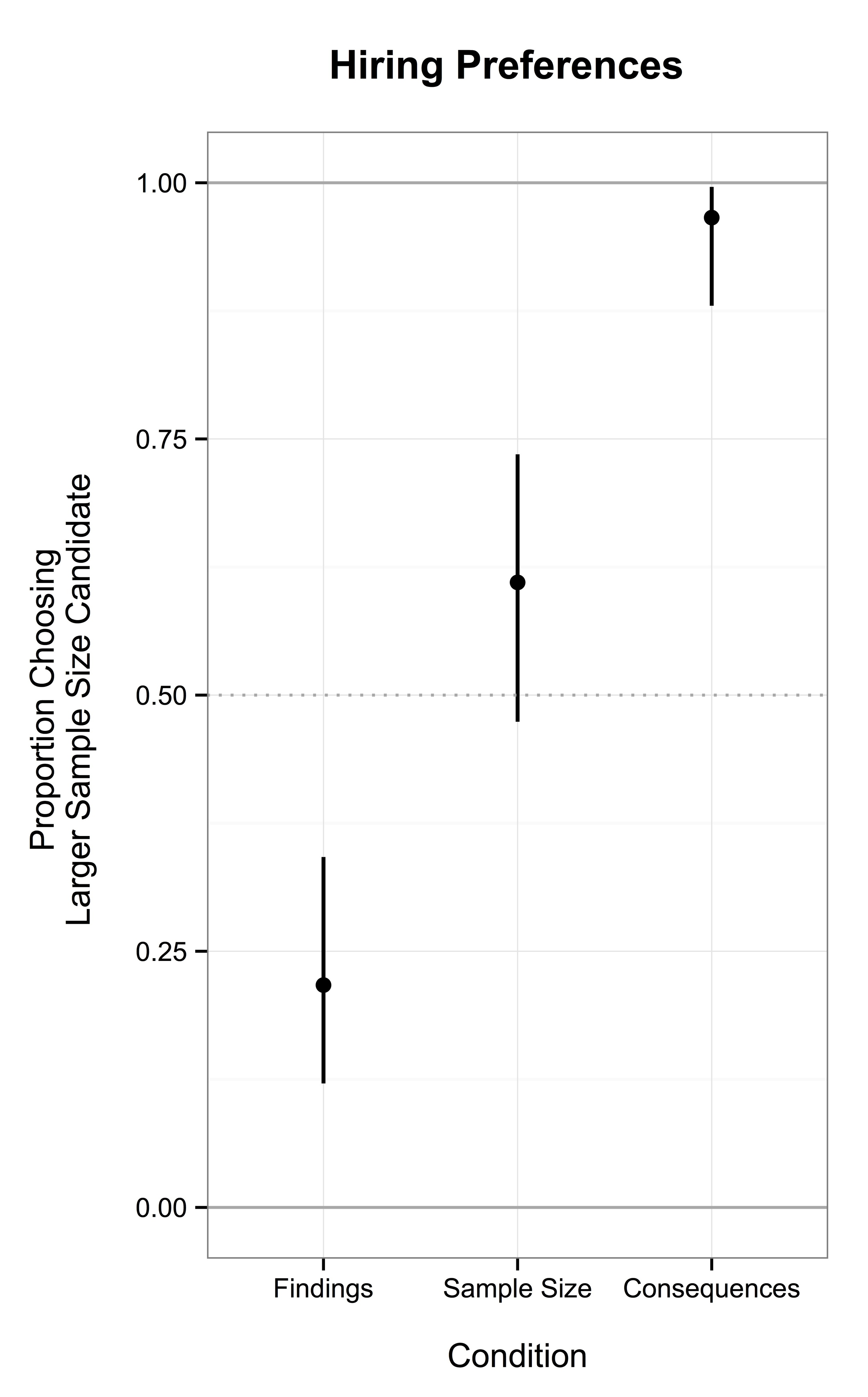
Wow, that's a big graph. I'm lousy at things like blogging, and I don't know how to resize it. Oh yeah, the error bars are 95% CIs for those of you keeping score at home.
There you have it. If you only tell people that one researcher publishes 56% more research, people prefer productivity. Makes sense. When you add in the sample size information, the reaction is mixed. It looks like they slightly (but not significantly) lean towards the bigger sample size candidate. But when the consequences are made explicit, people pretty much unanimously prefer the larger sample size candidate.
What does this mean? My one sentence summary would go something like this: Researchers are intolerant of the negative consequences of low power research, but merely indifferent regarding the practices that logically lead to those consequences.
My reaction?
I think this is really good news! That's right, good news!

Third time's a charm: it's good news.
Pretty much everyone wants to reward power over "mere" productivity when the consequences of low power research are made plain. This is great!
Why is it great? Well, as I mentioned, I think that one of the big issues facing our science is an incentive mismatch between what's good for the collective enterprise of science (more power = better) and what might be rewarded through the bottlenecks for individual researchers (productivity). But the incentives aren't being handed to us by some nefarious alien overlords.
Who reviews papers? Fellow researchers.
Who sits on hiring and promotion committees? Fellow researchers.
We are the ones who decide which papers get published. We decide who gets the jobs. We decide who gets tenure. We set the incentives. And when the consequences are clear, so too is the incentive. Power is rewarded. At least in this silly little thought experiment.
Now, there's more stuff in the paper. We discuss possible downsides to running bigger studies (spoiler alert: this could disproportionately hurt junior faculty, researchers at institutions without ginormous undergrad subject pools, and folks who study special populations...I don't have any good solutions here, and that bugs me). So you can read the paper for all those details.
I guess my take home message is something like this: If we want to increase power instead of just citing classic power papers into the ground, we need to carefully consider the consequences of power when designing and evaluating studies, as well as when evaluating researchers and bodies of literature.

PS...this was the first study I've ever preregistered and done fully through OSF. That was pretty cool.
PPS...I should fully acknowledge that back in the day I've run and published some really shitty small sample studies (I think my record worst has something like 13 participants in a condition...ouch). I view some of these studies much like I view that time in high school when I bleached my hair blond before a ski race, then my mom tried to fix it by dyeing it brown, and it resulted in me having awkward red hair for a couple of months. I won't claim that I never did it. I blush at the choices in hindsight, but I won't try to distance myself from them. I did it, but I won't do it again. Now I know better. I think that a lot of the replicability discussions in the field are great at getting people to introspect about what they're doing, and try to do better in the future. And the first step on that road is saying "oops" without shame. Well, maybe a little shame...that hair was ugly. I'll try to find a picture to post.